In the era of advanced artificial intelligence, Large Language Models (LLMs) have revolutionized how machines process and generate human language. At the heart of these sophisticated systems lies a crucial preprocessing technique called Byte Pair Encoding (BPE). This tokenization method bridges the gap between raw text and the numerical representations that LLMs can understand, making it possible for models to process language efficiently and effectively.
Fundamentals of Tokenization in Language Processing
A Deep Dive into How Byte Pair Encoding Powers Large Language Models
Large Language Models (LLMs) process text in a fundamentally different way than humans do. Instead of reading word by word, they work with tokens – smaller units that can represent characters, parts of words, or entire words. At the heart of this process is Byte Pair Encoding (BPE), a clever technique that breaks down text into manageable pieces.
Why Tokens Matter
Think of tokens as the basic building blocks LLMs use to understand language. Before an LLM can process any text, it needs to convert that text into numbers. This conversion happens through tokenization, and BPE is one of the most effective ways to do it.
For example, the word “understanding” might be split into tokens like “under” and “standing” because these pieces appear frequently in English text. This is more efficient than processing the word character by character, and more flexible than treating each complete word as a single token.
The Power of BPE
BPE brings several key advantages to language models:
- It finds common patterns in text automatically
- It works across different languages without modification
- It handles rare words by breaking them into familiar pieces
- It keeps vocabulary size manageable while maintaining meaning
Consider how BPE handles the word “cryptocurrency.” Instead of needing a single token for this relatively new word, BPE might break it into “crypto” and “currency” – pieces it already knows from other contexts. This allows LLMs to understand new combinations of familiar concepts.
Byte Pair Encoding: Core Mechanics
Byte Pair Encoding (BPE) transformed from a simple text compression method into the backbone of modern language model tokenization. But how does it actually work?
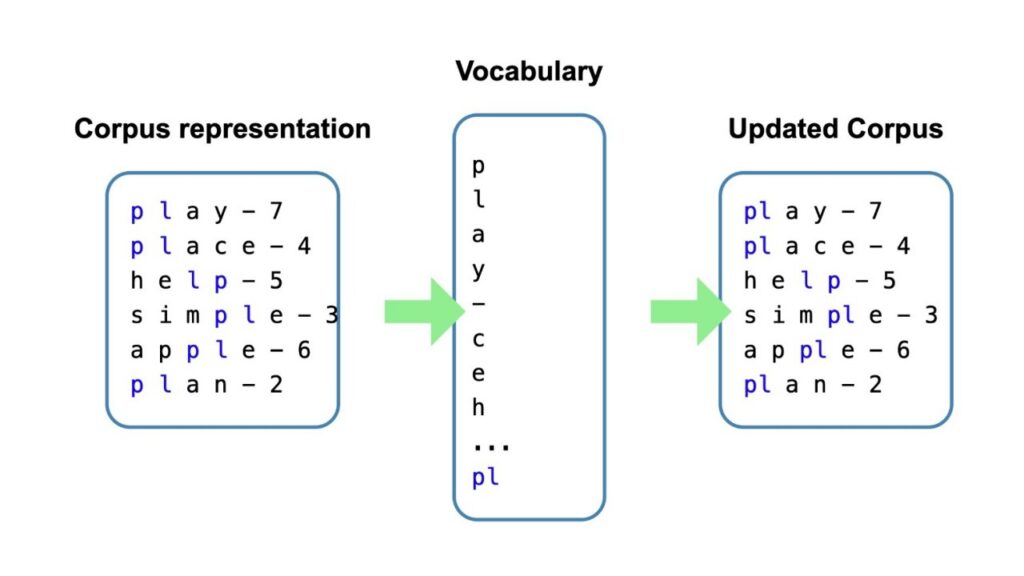
The Core BPE Algorithm
BPE follows a straightforward process:
- Start with individual characters as the base vocabulary
- Count all adjacent character pairs in the training text
- Merge the most frequent pair into a new token
- Repeat until reaching the desired vocabulary size
For example, if “er” appears frequently in words like “lower,” “higher,” and “faster,” BPE combines these characters into a single token. This process builds an efficient vocabulary that captures common patterns in the language.
Why BPE Shines in Language Models
BPE offers several key advantages that make it ideal for Large Language Models (LLMs):
- Handles unknown words by breaking them into familiar subwords
- Balances vocabulary size and text coverage
- Works across multiple languages without modification
- Preserves meaningful word components (like prefixes and suffixes)
From Text to Tokens: The Process
When an LLM processes text, the BPE tokenizer:
- Converts the input text to UTF-8 bytes
- Applies the learned merge rules in order
- Splits the text into tokens based on the vocabulary
Consider the word “unstoppable”. A BPE tokenizer might split it into “un” + “stop” + “able”, using common subwords it learned during training. This helps the model understand the meaning through familiar components.
Technical Implementation
Modern LLMs use optimized BPE implementations that improve on the basic algorithm. For instance, GPT models use a variant called byte-level BPE, which ensures any Unicode text can be processed without special handling.
The vocabulary size varies by model:
- Most LLMs use 30,000 to 50,000 tokens
- Larger models may use over 100,000 tokens
- The size balances coverage against memory and processing requirements
BPE’s efficiency comes from its ability to find the optimal balance between token frequency and meaningful subword units. The algorithm tracks usage statistics and merges pairs that maximize compression while preserving linguistic patterns.
Practical Benefits
This approach delivers real advantages:
- Reduces token count for common phrases
- Maintains readability of rare words
- Supports efficient model training
- Enables cross-lingual capabilities
For example, technical terms like “neural” and “network” might each be single tokens because they appear often in AI literature, while rare words get split into interpretable pieces.
BPE’s Role in Modern Language Models
Building on our understanding of BPE’s core mechanics, let’s explore how this tokenization method fundamentally shapes modern Large Language Models (LLMs). The way BPE breaks down text affects everything from model training to inference.
Why LLMs Need BPE
Modern language models process text as sequences of tokens, not raw characters. Byte Pair Encoding solves three critical challenges:
- Vocabulary size management – Instead of millions of whole words, BPE creates a smaller set of subword tokens
- Out-of-vocabulary handling – New or rare words can be broken into known subword pieces
- Compression efficiency – Common patterns get their own tokens, reducing sequence lengths
Impact on Model Architecture
BPE’s design influences key aspects of LLM architecture:
- Input embedding size matches the BPE vocabulary size
- Position encodings align with BPE token sequences
- Attention mechanisms operate on BPE token boundaries
For example, GPT-3 uses a 50,257-token vocabulary created through BPE. This determines the size of its input embedding matrix and shapes how the model processes text.
Training Considerations
When training LLMs, BPE affects several key areas:
- Data preprocessing – Raw text must be consistently tokenized using the same BPE rules
- Batch construction – Sequences are padded to match BPE token lengths
- Loss calculation – The model predicts the next BPE token, not the next character or word
Semantic Understanding
Research shows that BPE tokenization influences how LLMs develop semantic understanding:
- Common words stay whole, preserving their semantic unity
- Morphemes (word parts that carry meaning) often become single tokens
- Related words share subword tokens, helping models recognize patterns
Practical Implications
The way BPE works affects how we use LLMs:
- Input processing must match the model’s BPE tokenization exactly
- Token limits are based on BPE tokens, not raw characters
- Cost calculations for API calls often use BPE token counts
For multilingual models, BPE helps handle different scripts and character sets efficiently. It automatically adapts to the statistical patterns of each language in the training data.
Recent Advances
New research continues to improve how BPE works in LLMs:
- Topic modeling in BPE token space
- Optimized vocabulary selection for specific domains
- Enhanced handling of numerical and special characters
These improvements help LLMs better understand and generate text while maintaining computational efficiency.
Advanced Applications and Variations
The Core BPE Process
Byte Pair Encoding (BPE) works through a systematic process of identifying and combining frequent character pairs into new tokens. While the previous chapter covered its role in language models, let’s examine exactly how it processes text:
- Start with individual characters as the base vocabulary
- Count all adjacent character pairs in the training data
- Merge the most frequent pair into a new token
- Update the text with the new merged tokens
- Repeat until reaching the target vocabulary size
A Practical Example
Let’s see how BPE handles the word “learning” step by step:
- Initial tokens: l, e, a, r, n, i, n, g
- First merge: Most common pair “in” becomes “in”
- Result: l, e, a, r, n, in, g
- Next merge: If “ea” is frequent, it becomes one token
- Result: l, ea, r, n, in, g
Implementation Details
Modern language models typically use vocabularies of 50,000 to 100,000 tokens. The exact size balances compression against precision. Smaller vocabularies mean more tokens per word but better handling of rare cases. Larger vocabularies capture more complete words but need more memory.
Byte-Level Implementation
Byte-level BPE adds an important twist to the basic algorithm. Instead of working with raw characters, it:
- Converts text to UTF-8 bytes first
- Treats these bytes as the basic units
- Ensures any text can be tokenized without unknown tokens
- Handles all Unicode characters efficiently
Performance Optimizations
Real-world BPE implementations use several optimizations:
- Frequency caching: Store pair counts to avoid repeated scans
- Parallel processing: Split the corpus for faster pair counting
- Pruning: Remove rare tokens to prevent vocabulary bloat
- Regular expression acceleration: Use regex for faster token matching
Error Handling and Edge Cases
BPE includes built-in mechanisms for handling challenging text:
- Spaces get special treatment as word boundaries
- Numbers split into logical digit groups
- Punctuation marks become separate tokens
- Unicode symbols split into byte sequences
Memory and Speed Tradeoffs
The implementation involves key tradeoffs:
- Larger vocabularies mean faster processing but more memory use
- Smaller vocabularies compress better but need more tokens per word
- Cache size affects speed versus memory usage
- Preprocessing steps add initial overhead but improve runtime speed
These technical details show why BPE became the foundation for modern language models. It offers a practical balance of speed, memory efficiency, and linguistic understanding that scales well to massive datasets.
Future Developments and Optimization
The Foundation of Modern LLM Processing
Large Language Models (LLMs) process text through a critical first step: converting human-readable words into numbers. At the heart of this conversion lies Byte Pair Encoding (BPE), a clever method that breaks text into meaningful pieces called tokens.
BPE strikes a perfect balance between character-level and word-level tokenization. It creates a vocabulary of subword units that captures common patterns in language while keeping the total number of tokens manageable. Most modern LLMs use vocabularies of 50,000 to 100,000 tokens.
How BPE Works in Practice
The process follows these steps:
- Start with individual characters as tokens
- Count pairs of adjacent tokens
- Merge the most frequent pair into a new token
- Repeat until reaching the desired vocabulary size
This approach naturally discovers meaningful units like common prefixes (un-, re-), suffixes (-ing, -ed), and word stems. For example, “running” might become [“run”, “ning”], allowing the model to recognize parts of new words it encounters.
Benefits for Language Models
BPE provides several key advantages:
- Efficient compression: Text sequences become 1.3x shorter on average
- Better handling of rare words by breaking them into familiar pieces
- Automatic discovery of meaningful language patterns
- Guaranteed encoding of any text through byte-level fallback
Modern Implementations
Current LLMs use sophisticated versions of BPE. Models like GPT-2, RoBERTa, and BERT implement byte-level BPE, which first converts text to UTF-8 bytes. This ensures the system can handle any character in any language.
Latest Developments
Recent advances in tokenization include:
- Dynamic vocabularies that adapt to different content types
- Improved handling of multiple languages in the same text
- Better processing of technical content and code
- More efficient token allocation for non-English languages
These improvements help models process text more naturally across languages and domains while maintaining computational efficiency.
Challenges and Future Directions
Current research focuses on several areas:
- Reducing token count differences between languages
- Handling languages with unique writing systems more effectively
- Developing context-aware tokenization methods
- Creating more efficient multilingual vocabularies
As models grow more sophisticated, tokenization continues to evolve, balancing the need for efficient processing with better language understanding across diverse contexts.
Conclusions
BPE tokenization represents a crucial breakthrough in making large language models practical and effective. Its elegant balance between efficiency and effectiveness has made it the backbone of modern NLP systems. As language models continue to evolve, BPE and its variants will likely remain fundamental to their architecture, while new innovations build upon its solid foundation.